How do I connect to Hadoop server
By David Edwards
In the PDI client, create a new job or transformation or open an existing one.Click the View tab.Right-click the Hadoop clusters folder, then click New. The Hadoop Cluster window appears.You can now Configure and Test the Hadoop Cluster connection.
How do I connect Hadoop master and client?
- Install Hive and Pig on Master Node.
- Install Hive and Pig on Client Node.
- Now Start Coding pig/hive on client node.
How do I enable Hadoop?
- start-all.sh & stop-all.sh. Used to start and stop Hadoop daemons all at once. …
- start-dfs.sh, stop-dfs.sh and start-yarn.sh, stop-yarn.sh. …
- hadoop-daemon.sh namenode/datanode and yarn-deamon.sh resourcemanager. …
- Note : You should have ssh enabled if you want to start all the daemons on all the nodes from one machine.
What is a Hadoop server?
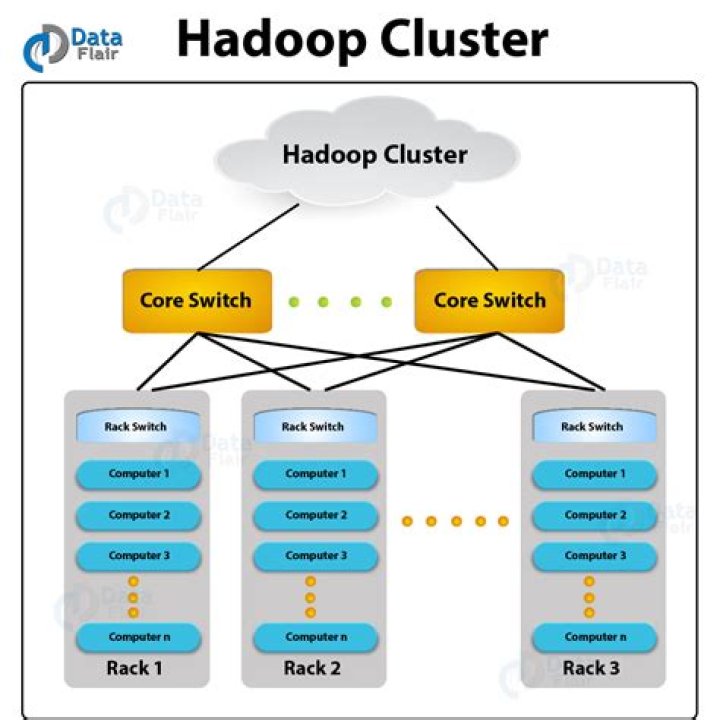
Hadoop is an open source, Java based framework used for storing and processing big data. The data is stored on inexpensive commodity servers that run as clusters. Its distributed file system enables concurrent processing and fault tolerance. Developed by Doug Cutting and Michael J.Can you run Hadoop locally?
Hadoop can also be run on a single-node in a pseudo-distributed mode where each Hadoop daemon runs in a separate Java process.
How do you check if hadoop is installed properly?
Your answer You just have to type ‘jps’ (make sure JDK is installed in your system). It lists all the running java processes and will list out the Hadoop daemons that are running. You can also check if the daemons are running or not through their web ui.
What are the prerequisites to install hadoop?
- 1) Intel Core 2 Duo/Quad/hex/Octa or higher end 64 bit processor PC or Laptop (Minimum operating frequency of 2.5GHz)
- 2) Hard Disk capacity of 1- 4TB.
- 3) 64-512 GB RAM.
- 4) 10 Gigabit Ethernet or Bonded Gigabit Ethernet.
How do I download and install Hadoop?
- Step 1: Click here to download the Java 8 Package. …
- Step 2: Extract the Java Tar File. …
- Step 3: Download the Hadoop 2.7.3 Package. …
- Step 4: Extract the Hadoop tar File. …
- Step 5: Add the Hadoop and Java paths in the bash file (. …
- Step 6: Edit the Hadoop Configuration files. …
- Step 7: Open core-site.
How do I install Hadoop on Windows 10?
- Step 1 – Download Hadoop binary package. …
- Step 2 – Unpack the package. …
- Step 3 – Install Hadoop native IO binary. …
- Step 4 – (Optional) Java JDK installation. …
- Step 5 – Configure environment variables. …
- Step 6 – Configure Hadoop. …
- Step 7 – Initialise HDFS & bug fix.
Big Data is treated like an asset, which can be valuable, whereas Hadoop is treated like a program to bring out the value from the asset, which is the main difference between Big Data and Hadoop. Big Data is unsorted and raw, whereas Hadoop is designed to manage and handle complicated and sophisticated Big Data.
Article first time published onHow do I start hadoop daemons?
- start-all.sh and stop-all.sh.
- start.dfs.sh, stop.dfs.sh and start-yarn.sh, stop-yarn.sh.
- hadoop.daemon.sh start namenode/datanode and hadoop.daemon.sh stop namenode/datanode.
Where is hadoop installed?
Navigate to the path where hadoop is installed. locate ${HADOOP_HOME}/etc/hadoop , e.g. When you type the ls for this folder you should see all these files. Core configuration settings are available in hadoop-env.sh.
Where is start-all sh hadoop?
start-all.sh and stop-all.sh are located in sbin directory while hadoop binary file is located in bin directory.
How do I run Hadoop on Windows?
- Edit the file core-site.xml in the hadoop directory. …
- Edit mapred-site.xml and copy this property in the cofiguration. …
- Create a folder ‘data’ in the hadoop directory. …
- Edit the file hdfs-site.xml and add below property in the configuration.
Where do Hadoop commands run?
Type a Hadoop File System Command in the Hadoop Shell Command Input field. The input is run as one command, for example: hadoop fs -ls /. Typing the hadoop fs command enables the Submit button.
How do I start Hadoop in terminal?
Run the command % $HADOOP_INSTALL/hadoop/bin/start-dfs.sh on the node you want the Namenode to run on. This will bring up HDFS with the Namenode running on the machine you ran the command on and Datanodes on the machines listed in the slaves file mentioned above.
What should I learn before Hadoop?
- Programming Skills. Hadoop requires knowledge of several programming languages, depending on the role you want it to fulfill. …
- SQL Knowledge. Knowledge of SQL is essential regardless of the role you want to pursue in Big Data. …
- Linux.
How much Linux is required for Hadoop?
Hello. Knowing basics of Linux is mandatory but you dont really need to be a Master in Linux. Basic knowledge on Linux environment, commands are enough to start learning Hadoop.
Can Hadoop run on 4GB RAM?
for learning, you can install Pseudo node hadoop on 4GB ram with out any issue. 4GB is not good to run a Hadoop system. It’s memory intensive and will slow down or crash your system at last.
Can we run Hadoop online?
You should be able to run this on any Windows / Mac / Linux machine so long as you have enough disk space and RAM. Similar downloads also exist for the other major distributors of Hadoop. There are also links on the same page for accessing an online sandbox via Microsoft Azure.
How do I view Hadoop files in my browser?
- To access HDFS NameNode UI from Ambari Server UI, select Services > HDFS.
- Click Quick Links > NameNode UI. …
- To browse the HDFS file system in the HDFS NameNode UI, select Utilities > Browse the file system . …
- Enter the directory path and click Go!.
How do I install Hadoop and Spark on Windows 10?
- Step 1: Install Java 8.
- Step 2: Install Python.
- Step 3: Download Apache Spark.
- Step 4: Verify Spark Software File.
- Step 5: Install Apache Spark.
- Step 6: Add winutils.exe File.
- Step 7: Configure Environment Variables.
- Step 8: Launch Spark.
Which software is used for Hadoop?
The Apache™ Hadoop® project develops open-source software for reliable, scalable, distributed computing. The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models.
Does Hadoop require coding?
Although Hadoop is a Java-encoded open-source software framework for distributed storage and processing of large amounts of data, Hadoop does not require much coding. … All you have to do is enroll in a Hadoop certification course and learn Pig and Hive, both of which require only the basic understanding of SQL.
What is the difference between Hadoop and Apache Hadoop?
No.Big DataApache Hadoop4Big Data is harder to access.It allows the data to be accessed and process faster.
Who owns Hadoop?
Original author(s)Doug Cutting, Mike CafarellaDeveloper(s)Apache Software FoundationInitial releaseApril 1, 2006
What is spark vs Hadoop?
Apache Hadoop and Apache Spark are both open-source frameworks for big data processing with some key differences. Hadoop uses the MapReduce to process data, while Spark uses resilient distributed datasets (RDDs).
What is Hadoop FS command?
The Hadoop fs shell command put is similar to the copyFromLocal, which copies files or directory from the local filesystem to the destination in the Hadoop filesystem.
What are the Hadoop Daemons and explain them?
In computing terms, Daemons is a process that runs in the background. Hadoop has five such daemons, namely NameNode, Secondary NameNode, DataNode, JobTracker, and TaskTracker. Each daemons runs separately in its own JVM.
How do I start Hadoop services in Ubuntu?
- Install OpenJDK on Ubuntu.
- Set Up a Non-Root User for Hadoop Environment. Install OpenSSH on Ubuntu. …
- Download and Install Hadoop on Ubuntu.
- Single Node Hadoop Deployment (Pseudo-Distributed Mode) Configure Hadoop Environment Variables (bashrc) …
- Format HDFS NameNode.
- Start Hadoop Cluster.
- Access Hadoop UI from Browser.
Which set of files do we need to configure during installation of hadoop?
- Read-only default configuration – src/core/core-default. xml, src/hdfs/hdfs-default. xml and src/mapred/mapred-default. xml.
- Site-specific configuration – conf/core-site. xml, conf/hdfs-site. xml and conf/mapred-site. xml.