What is MTTD and MTTR
By Andrew Hansen
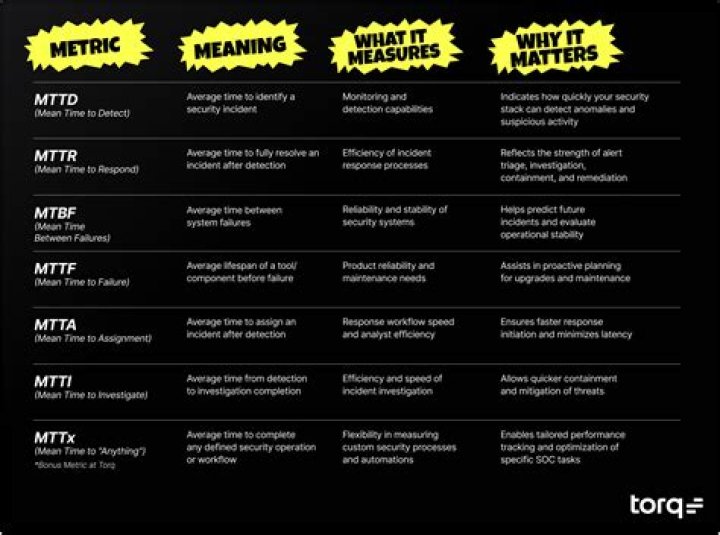
Mean time to detect, or MTTD, reflects the amount of time it takes your team to discover a potential security incident. Mean time to respond, or MTTR, is the time it takes to control, remediate and/or eradicate a threat once it has been discovered.
What is MTTD?
Mean time to detect (MTTD) is one of the main key performance indicators in incident management. It refers to the mean amount of time it takes for the organization to discover—or detect—an incident. The sooner an organization finds out about a problem, the better.
How is MTTD calculated?
To find the MTTD, simply add all the incident detection times for the given team member or time period and divide by the number of incidents. For instance, if your total time to detection for January is 850 minutes, and there were 12 incidents reported, your mean time to detect would be 70.83 minutes.
What is the meaning of MTTR and MTBF?
Mean Time Between Failures and Mean Time To Repair. MTBF (Mean Time Between Failures) and MTTR (Mean Time To Repair) are two very important indicators when it comes to availability of an application.Why are MTTD and MTTR important?
This is why metrics such as MTTR (Mean time to respond) and MTTD (Mean time to detect) have grown to be highly relevant in the cybersecurity industry. The reason that these metrics are so important is that they visually represent how good your security team is at detecting and remediating threats.
How do you lower MTTD?
People are the biggest factor in reducing MTTD and MTTR This is accomplished through education and constant training. For starters, ensure your security team fully understands your incident response processes and life cycles, common attacks and hacker techniques, and best practices for how to defend against them.
What does MTTD stand for in DevOps?
Sure enough, MTTD stands for “Mean time to detect.” It refers to an important KPI (key performance indicator) in DevOps.
What is MTTR?
MTTR (mean time to recovery or mean time to restore) is the average time it takes to recover from a product or system failure. This includes the full time of the outage—from the time the system or product fails to the time that it becomes fully operational again.What is MTTR and MTBF in SAP PM?
We know that MTTR (Mean Time to Repair in Hrs) = ( D1 + D2 + D3 + D4 + D5 + D6 ) / 6 = 18 . Similarly MTBR (Mean Time Between Repairs in Hrs) = ( U1 + U2 +U3 + U4 + U5 + U6 + U7 ) / 6 = 150 . Now, Equipment Availability (%) is: UpTime / Total Time = (900 / 1008) * 100 = 89.2.
What do you mean by MTBF?Mean time between failures (MTBF) is the average time between system breakdowns. MTBF is a crucial maintenance metric to measure performance, safety, and equipment design, especially for critical or complex assets, like generators or airplanes.
Article first time published onWhat is KPI in DevOps?
Key Performance Indicators are metrics widely used to know how good (or bad) are some practices, products, projects or even initiatives. Well, planning projects define KPIs that are collected from day zero and followed in all steps.
What is time to detection?
A key performance indicator (KPI) within IT incident management, mean time to detect (MTTD) refers to the average time passed between the onset of an IT incident and its discovery.
What is lead time in Devops?
In simple terms, the lead time is the time it takes to implement, test, and deliver code. … The aim is to increase the speed of deployment through automation such as an optimization of the integration of the testing process to shorten overall time to deployment.
What is the difference between MTBF and MTBR?
Mean time between repairs differs from MTBF in that MTBF typically counts only how long a product operates before failure, whereas MTBR would inherently include the time spent on repair, which can make a big difference in the final outcome.
What is the role of SIEM?
SIEM collects security data from network devices, servers, domain controllers, and more. SIEM stores, normalizes, aggregates, and applies analytics to that data to discover trends, detect threats, and enable organizations to investigate any alerts.
What is the difference between RTO and MTTR?
The RTO is similar, but not identical, to the MTTR used in disaster recovery. The difference is that RTO is the maximum expected time by which service is expected to be restored, whereas MTTR is the elapsed recovery time averaged over a specified time period.
How can I improve my MTTR?
- Create a robust incident-management action plan.
- Define roles in your incident-management command structure.
- Train the entire team on different roles and functions.
- Monitor, monitor, monitor.
- Leverage AIOps capabilities to detect, diagnose, and resolve incidents faster.
What is deployment frequency?
Deployment Frequency is a core DevOps metric and more broadly a core Agile delivery metric. As the name suggest it tracks the frequency with which increments of code are deployed to staging, testing and production.
How long does it take to detect a data breach?
The average time to identify a breach in 2020 was 228 days (IBM). The average time to contain a breach was 80 days (IBM). Healthcare and financial industries spent the most time in the data breach lifecycle, 329 days and 233 days, respectively (IBM).
What does the term Siem stand for?
Security information and event management (SIEM) technology supports threat detection, compliance and security incident management through the collection and analysis (both near real time and historical) of security events, as well as a wide variety of other event and contextual data sources.
How do you calculate MTBF in Excel?
- MTBF = 22.5 / 2.
- MTBF = 11.25 hours.
How do you calculate reliability?
Reliability is complementary to probability of failure, i.e. R(t) = 1 –F(t) , orR(t) = 1 –Π[1 −Rj(t)] . For example, if two components are arranged in parallel, each with reliability R 1 = R 2 = 0.9, that is, F 1 = F 2 = 0.1, the resultant probability of failure is F = 0.1 × 0.1 = 0.01.
What is Mtbsi?
Mean time between system incidents (MTBSI): The average elapsed time between the detection of two consecutive incidents. MTBSI can be calculated by adding MTBF and MTRS (MTBSI = MTBF + MTRS). … It is expressed as a number of failures over a unit of time.
What affects MTTR?
MTTR depends on multiple factors like the type of asset you’re analyzing, its age, criticality, maintenance team training, etc.
How is MTTR calculated in Odoo?
MTTR can be calculated by dividing the total time required for maintenance — downtime — by the total number of repairs within a specific time frame.
How is MTBF and MTTR calculated with example?
The “availability” of a device is, mathematically, MTBF / (MTBF + MTTR) for scheduled working time. The automobile in the earlier example is available for 150/156 = 96.2% of the time. The repair is unscheduled down time.
How do you fix MTTR and MTBF targets?
- Optimize spare parts management and asset inventory management processes. …
- Use condition-monitoring sensors to track machine health and performance. …
- Implement CMMS software. …
- Streamline the repair process. …
- Proper training.
What is MTTR and MTBF PDF?
Mean Time Between Failure (MTBF) is a reliability term used to provide the amount of failures per million hours for a product. … Mean Time To Repair (MTTR) is the time needed to repair a failed hardware module. In an op- erational system, repair generally means replacing a failed hardware part.
What is monitoring tools in DevOps?
DevOps monitoring tools provide a comprehensive view of a production environment in real-time, automation, and expanded management throughout the application lifecycle – from planning, development and testing to deployment and operations.
How is DevOps measured?
- 1: Deployment frequency.
- 2: Change failure rate.
- 3: Mean Time to Recovery (MTTR)
- 4: Lead time.
- 5: Change volume.
- 6: Defect escape rate.
- 7: Customer tickets.
- 8: DevOps Resources.
What is the value of DevOps?
Collaboration & communication When considering the universal core values of DevOps, the primary value is collaboration. DevOps is focused on bridging the gap between different teams and creating a collaborative environment where all teams are working together to benefit the product.