
What is the use of parquet format
By Olivia Hensley
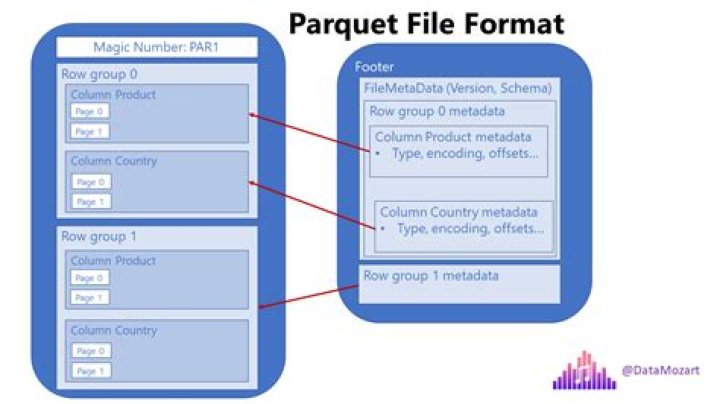
What is Parquet? Parquet is an open source file format available to any project in the Hadoop ecosystem. Apache Parquet is designed for efficient as well as performant flat columnar storage format of data compared to row based files like CSV or TSV files.
What is the benefit of a parquet file?
Benefits of Storing as a Parquet file: Low storage consumption. Efficient in reading Data in less time as it is columnar storage and minimizes latency. Supports advanced nested data structures. Optimized for queries that process large volumes of data.
Why is parquet used for spark SQL?
Parquet is a columnar format that is supported by many other data processing systems. Spark SQL provides support for both reading and writing Parquet files that automatically preserves the schema of the original data.
When should I use parquet?
Parquet is optimized for the Write Once Read Many (WORM) paradigm. It’s slow to write, but incredibly fast to read, especially when you’re only accessing a subset of the total columns. For use cases requiring operating on entire rows of data, a format like CSV, JSON or even AVRO should be used.How is data stored in parquet?
This simply means that data is encoded and stored by columns instead of by rows. This pattern allows for analytical queries to select a subset of columns for all rows. Parquet stores columns as chunks and can further split files within each chunk too.
Is parquet a database?
Initial release13 March 2013Operating systemCross-platformTypeColumn-oriented DBMSLicenseApache License 2.0Websiteparquet.apache.org
Is parquet better than CSV?
Parquet performance, when compared to a format like CSV, offers compelling benefits in terms of cost, efficiency, and flexibility. The following demonstrates the efficiency and effectiveness of using a Parquet file vs.
Is reading Parquet faster than CSV?
In this article, we will show that using Parquet files with Apache Arrow gives you an impressive speed advantage compared to using CSV files with Pandas while reading the content of large files.Which data format is faster?
rjson. rjson is the fastest JSON implementation – only 10 times slower than msgpack , in memory, and 2.7 times slower across the wire.
Is Parquet human readable?ORC, Parquet, and Avro are also machine-readable binary formats, which is to say that the files look like gibberish to humans. If you need a human-readable format like JSON or XML, then you should probably re-consider why you’re using Hadoop in the first place.
Article first time published onWhy parquet is best for spark?
1- Columnar storage limits IO operations. 2- Columnar storage can fetch specific columns that you need to access. 3-Columnar storage consumes less space. 4- Columnar storage gives better-summarized data and follows type-specific encoding.
Does parquet have schema?
Parquet file is an hdfs file that must include the metadata for the file. This allows splitting columns into multiple files, as well as having a single metadata file reference multiple parquet files. The metadata includes the schema for the data stored in the file.
How do you write data in parquet format?
- Create a DataFrame. For example: …
- Write to the DataFrame using df.write.parquet. The argument is the path to the Cloud Object Storage, which you can obtain using cos.url(filenametowrite,bucketnameforyourproject). …
- Read that written DataFrame back. For example:
Is Parquet compressed by default?
By default Big SQL will use SNAPPY compression when writing into Parquet tables. This means that if data is loaded into Big SQL using either the LOAD HADOOP or INSERT… SELECT commands, then SNAPPY compression is enabled by default.
What is Parquet AWS?
Parquet is an efficient columnar data storage format that supports complex nested data structures in a flat columnar format. Parquet is perfect for services like AWS Athena andAmazon Redshift Spectrum which are serverless, interactive technologies.
Can Excel open Parquet?
Read, Write, and Update Parquet from Excel The Parquet Excel Add-In is a powerful tool that allows you to connect with live Parquet data, directly from Microsoft Excel.
Is Parquet faster than Avro?
Avro is fast in retrieval, Parquet is much faster. parquet stores data on disk in a hybrid manner. It does a horizontal partition of the data and stores each partition it in a columnar way.
What is Parquet storage?
Parquet is an open source file format built to handle flat columnar storage data formats. Parquet operates well with complex data in large volumes.It is known for its both performant data compression and its ability to handle a wide variety of encoding types.
Is Parquet structured or unstructured?
Parquet is a columnar binary format. That means all your records must respect a same schema (with all columns and same data types !). The schema is stored in your files. Thus it is highly structured.
What is faster than NTFS?
The ext4 filesystem is also capable of performing faster file system checks than other equivalent journaling filesystems (e.g. NTFS).
What is the difference between parquet and Avro?
Comparisons Between Different File Formats AVRO is a row-based storage format, whereas PARQUET is a columnar-based storage format. PARQUET is much better for analytical querying, i.e., reads and querying are much more efficient than writing. Writiing operations in AVRO are better than in PARQUET.
What's faster FAT32 or NTFS?
Generally speaking, the slowest link (usually the hard drive interface to the PC like SATA) plays a role in the file transfer speed and maximum throughput, but the NTFS file system has been tested to be faster than FAT32 on most benchmarks.
Why is Parquet fast?
Parquet is built to support flexible compression options and efficient encoding schemes. As the data type for each column is quite similar, the compression of each column is straightforward (which makes queries even faster).
What is Parquet in Python?
The Apache Parquet project provides a standardized open-source columnar storage format for use in data analysis systems. … PyArrow includes Python bindings to this code, which thus enables reading and writing Parquet files with pandas as well.
How much faster is parquet than CSV?
Parquet files take much less disk space than CSVs (column Size on Amazon S3) and are faster to scan (column Data Scanned). As a result, the identical dataset is 16 times cheaper to store in Parquet format! Once again — yikes! Parquet is 99.7% cheaper if your original CSV file is 1TB in size.
Which file format is best for Hive?
Using ORC files improves performance when Hive is reading, writing, and processing data comparing to Text,Sequence and Rc. RC and ORC shows better performance than Text and Sequence File formats.
Which file format is best for spark?
The default file format for Spark is Parquet, but as we discussed above, there are use cases where other formats are better suited, including: SequenceFiles: Binary key/value pair that is a good choice for blob storage when the overhead of rich schema support is not required.
What are the benefits of Avro?
Avro supports polyglot bindings to many programming languages and a code generation for static languages. For dynamically typed languages, code generation is not needed. Another key advantage of Avro is its support of evolutionary schemas which supports compatibility checks, and allows evolving your data over time.
Does Parquet support null values?
Spark does support writing null values to numeric columns. and the result can be safely written to Parquet.
How do I read a parquet file in SQL?
- Open Spark Shell. Start the Spark shell using following example $ spark-shell.
- Create SQLContext Object. …
- Read Input from Text File. …
- Store the DataFrame into the Table. …
- Select Query on DataFrame.
How do I view parquet files in HDFS?
- Prepare parquet files on your HDFS filesystem. …
- Using the Hive command line (CLI), create a Hive external table pointing to the parquet files. …
- Create a Hawq external table pointing to the Hive table you just created using PXF. …
- Read the data through the external table from HDB.



