
What is Tsdb in Prometheus
By Christopher Green
Prometheus 2 time series database (TSDB) is an amazing piece of engineering, offering a dramatic improvement compared to “v2” storage in Prometheus 1 in terms of ingest performance, query performance and resource use efficiency.
Where is Prometheus Tsdb stored?
path : Where Prometheus writes its database. Defaults to data/ . –storage. tsdb.
What is Prometheus compaction?
The compactor component of Thanos applies the compaction procedure of the Prometheus 2.0 storage engine to block data stored in object storage. It is generally not semantically concurrency safe and must be deployed as a singleton against a bucket.
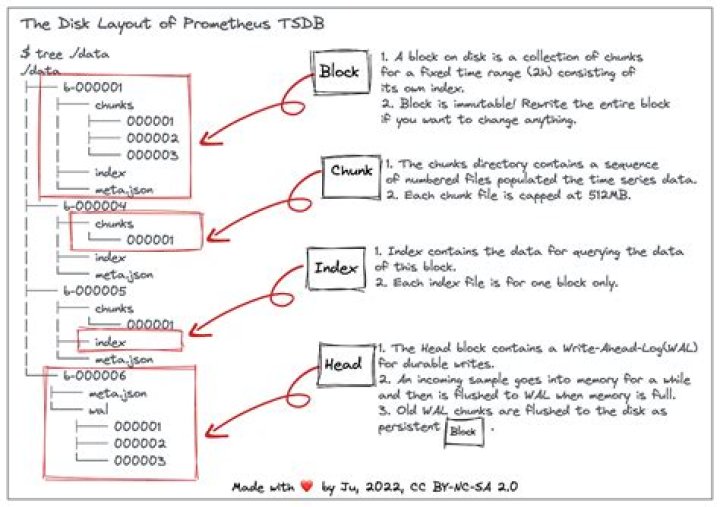
What is head block in Prometheus?
The head block is the in-memory part of the time series database (TSDB) embedded in Prometheus. It stores the last 1–3 hours of data in memory. The data is flushed to disk every 2 hours to form persistent blocks.What is chunks in Prometheus?
The samples are stored in compressed units called a “chunk”. When a sample is incoming, it is ingested into the “active chunk” (the red block). It is the only unit where we can actively write data.
How much RAM does my Prometheus need for ingestion?
You can expect RSS RAM usage to be at least 2.6kiB per local memory chunk. The chunks themselves are 1024 bytes, there is 30% of overhead within Prometheus, and then 100% on top of that to allow for Go’s GC.
How many metrics are there in Prometheus?
The Prometheus client libraries offer four core metric types.
How is data stored in Prometheus?
Prometheus has a sophisticated local storage subsystem. For indexes, it uses LevelDB. For the bulk sample data, it has its own custom storage layer, which organizes sample data in chunks of constant size (1024 bytes payload). These chunks are then stored on disk in one file per time series.How do you increase retention period in Prometheus?
- On the management node, open the /etc/sysconfig/prometheus file to edit, set the needed retention period for the STORAGE_RETENTION option, and save your changes. For example: …
- Restart the Prometheus service: systemctl restart prometheus.service.
To reduce memory consumption, Prometheus can be configured to store fewer time series, by scraping fewer metrics or by attaching fewer labels to the time series. To see which series use the most memory, you can check the TSDB (time series database) status page in the Prometheus UI.
Article first time published onHow do you scale Prometheus?
The most straightforward way to scale Prometheus is by using federation. Simply put, federation is the ability of one Prometheus server to scrape time-series data from another Prometheus server. Prometheus offers two types of federation: hierarchical and cross-service.
What is Prometheus Pushgateway?
The Prometheus Pushgateway allows you to push time series from short-lived service-level batch jobs to an intermediary job which Prometheus can scrape. Combined with Prometheus’s simple text-based exposition format, this makes it easy to instrument even shell scripts without a client library.
How can Prometheus reduce metrics?
Using metric_relabel_configs , you can drastically reduce your Prometheus metrics usage by throwing out unneeded samples. If shipping samples to Grafana Cloud, you also have the option of persisting samples locally, but preventing shipping to remote storage.
What is Go_memstats_alloc_bytes?
go_memstats_alloc_bytes – a metric which shows how much bytes of memory is allocated on the Heap for the Objects. The value is same as go_memstats_heap_alloc_bytes. This metric counts all reachable heap objects plus unreachable objects, GC has not yet freed.
What is Container_memory_rss?
“container_memory_rss” : The amount of anonymous and swap cache memory. “container_memory_working_set_bytes”: The amount of working set memory, this includes recently accessed memory, dirty memory, and kernel memory.
What is Thanos software?
Thanos is a metric system that provides a simple and cost-effective way to centralize and scale Prometheus based systems. The project was created at Improbable to enable reliable monitoring on a global scale.
What is Le in Prometheus metrics?
A histogram is a combination of various counters. Like summary metrics, histogram metrics are used to track the size of events, usually how long they take, via their observe method. … More particularly they’re counters which form a cumulative histogram, le stands for less than or equal to.
What are metrics used for?
Metrics are measures of quantitative assessment commonly used for comparing, and tracking performance or production. Metrics can be used in a variety of scenarios. Metrics are heavily relied on in the financial analysis of companies by both internal managers and external stakeholders.
How does Prometheus define metrics?
At this moment, for Prometheus, all metrics are time-series data. The Prometheus client libraries are the ones in charge of aggregating metrics data, like count or sum. Usually, these client libraries—like the Go library from the graphic above—have four types of metrics: counter, gauge, history, and summary.
How long is Prometheus data?
By default the retention is configured to 15 days. The amounts of data stored on disk depends on retention — higher retention means more data on disk. The lowest supported retention in Prometheus is 2 hours (2h).
What is Prometheus open source?
Prometheus is an open-source systems monitoring and alerting toolkit originally built at SoundCloud. Since its inception in 2012, many companies and organizations have adopted Prometheus, and the project has a very active developer and user community.
What is Prometheus cardinality?
Prometheus performance almost always comes down to one thing: label cardinality. Cardinality is how many unique values of something there are. … You might have a histogram covering 2 HTTP methods, 7 HTTP paths, 5 machines, and a Prometheus typically only monitors one environment and datacenter. So that’s 2x7x5x12 = 840.
What is the difference between Prometheus and Grafana?
Grafana and Prometheus, both help us in tackling issues related to complex data in a simplified manner. Grafana is an open-source visualization software, which helps the users to understand the complex data with the help of data metrics. … Prometheus is an open-source event monitoring and alerting tool.
How do I check my Prometheus data?
You can also visualize the data as charts, histograms, etc. To view the NRQL query results for your Prometheus integration’s data: Go to one.newrelic.com > Query your data. For more information, see New Relic’s query builder documentation.
Is Prometheus a time series database?
Prometheus is an open-source time series database developed by SoundCloud, and serves as the storage layer for the Prometheus monitoring system. … Prometheus contains a user-defined multi-dimensional data model and a query language on multi-dimensional data called PromQL.
How do I restore my Prometheus data?
- Log in to the source Admin Node: Enter the following command: ssh [email protected] grid_node_IP. …
- From the source Admin Node, stop the Prometheus service: service prometheus stop.
- Complete the following steps on the recovered Admin Node: …
- Restart the Prometheus service on the source Admin Node.
How do you create a rule in Prometheus?
To include rules in Prometheus, create a file containing the necessary rule statements and have Prometheus load the file via the rule_files field in the Prometheus configuration. Rule files use YAML. The rule files can be reloaded at runtime by sending SIGHUP to the Prometheus process.
Does Grafana store data?
Grafana works with data, which must be stored in a database before it can be accessed by Grafana. There are several different kinds of databases. Additionally, some other systems can be used to store data, even though their main purpose is not focused on data storage.
Why does Prometheus use so much RAM?
prometheus tsdb has a memory block which is named: “head”, because head stores all the series in latest hours, it will eat a lot of memory.
How do I make Prometheus highly available?
To run Prometheus in a highly available manner, two (or more) instances need to be running with the same configuration, that means they scrape the same targets, which in turn means they will have the same data in memory and on disk, which in turn means they are answering requests the same way.
What is Container_cpu_usage_seconds_total?
I found two metrics in prometheus may be useful: container_cpu_usage_seconds_total: Cumulative cpu time consumed per cpu in seconds. process_cpu_seconds_total: Total user and system CPU time spent in seconds.



